December 12, 2024
A Gentle Intro to Reinforcement Learning: Code Your First Q-Learning Algorithm

Have you noticed ever how computers can be trained to play games, run robots, and make difficult decisions? Reinforcement Learning (RL) allows computers to learn by interacting with their environment and receiving rewards or punishments. This blog post will teach you Q-Learning, which is one of the easiest and most useful RL methods. You will know the basics of RL and be able to code your own simple Q-learning algorithm by the end!
Understanding Q-Learning
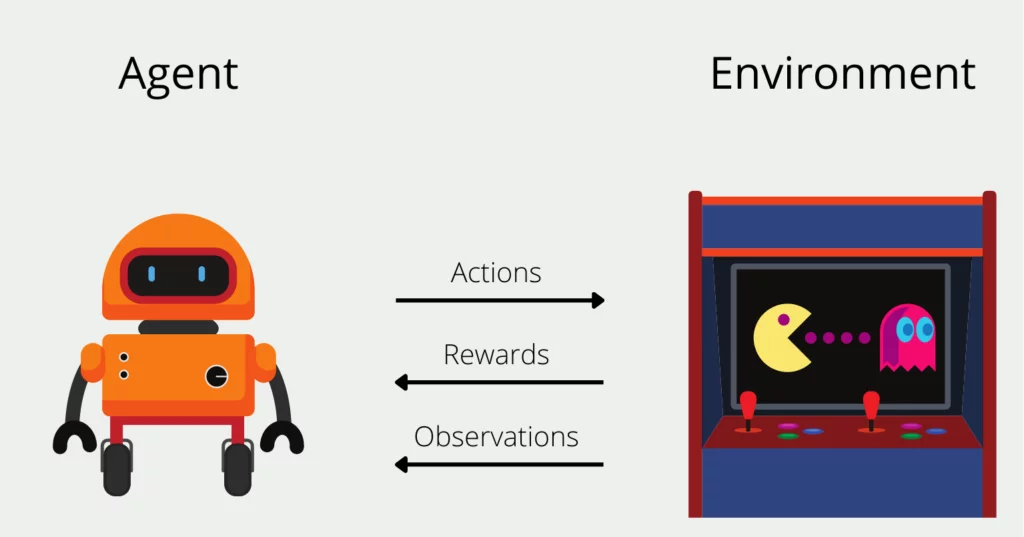
Q-Learning is one of the most important RL algorithms for figuring out what an agent should do to get the most benefits over time. An agent, such as a robot or computer program, interacts with a state-action environment. The environment rewards the machine for its actions. Q-learning teaches the agent the optimal policy, depending on its current condition, to take next.
Key Concepts in Q-Learning
Before coding, let us review Q-learning basics.
- Q-Values and Q-Table: Q-values show the predicted future benefits of particular actions in states. While, a Q-table stores these data, with rows representing states and columns actions.
- The Bellman Equation: This equation updates table Q-values. It balances present and future rewards, improving agent decision-making.
- Exploration vs. Exploitation: This balance is key in Q-learning. The agent must occasionally try new actions to find their rewards and use known actions to optimize rewards based on knowledge. By choosing a random action with probability epsilon and the best-known action otherwise, an epsilon-greedy strategy generally strikes this balance.
Implementing a Simple Q-Learning Algorithm
Initialize the Q-Table:
Start with a table of zeros, with rows for states and columns for actions.
import numpy as np
q_table = np.zeros((num_states, num_actions))
Loop through Episodes:
For each episode, the agent will:
- Select an Action: Use epsilon-greedy policy.
- Observe Reward and Next State: Perform the action and observe the environment's feedback.
- Update Q-Value: Use the Bellman equation to update the Q-table.
for episode in range(total_episodes):
state = initial_state
for step in range(max_steps):
# Choose action (epsilon-greedy)
if np.random.uniform(0, 1) < epsilon:
action = env.sample_action() # Explore
else:
action = np.argmax(q_table[state]) # Exploit
# Take action, observe result
new_state, reward = env.step(action)
# Update Q-value
q_table[state, action] = q_table[state, action] + \
alpha * (reward + gamma * np.max(q_table[new_state]) - q_table[state, action])
state = new_state
# End if done
if done:
break
Parameters to Tune:
- Alpha (learning rate): Controls how much we adjust new information.
- Gamma (discount factor): Balances immediate and future rewards.
- Epsilon: Adjusts the exploration-exploitation balance.
Conclusion and Next Steps
Congratulations! You've successfully coded a simple Q-learning algorithm. Q-learning is powerful, but deep learning (Deep Q-Networks) can solve more difficult issues. Keep trying different environments to discover what your agent can do!
1.1k views